
Google BERT & SEO: What You Need to Know
- Published
- 14 November 2019
- Read time
- 15 min read
Google's announcement of a new machine learning system named BERT has created a stir in the marketing industry. Read our explainer to find out how it impacts SEO.
Introduction
Google's self-proclaimed 'biggest change of the last five years' happened on October 25. But what is BERT, and what does it really mean for SEO?
TL;DR – BERT is not a ranking algorithm update, it's a way of processing natural language queries to surface better results and match user intent. Calls to 'optimise' for BERT are mistaken. What BERT does is connect more relevant searches to your information, provided you have been writing content that serves your users' needs.
What is BERT?
BERT is an open-source natural language processing (NLP) system designed to better understand the meaning and context of words and phrases.
It stands for Bidirectional Encoder Representations from Transformers. Essentially, it's a machine-learning method for understanding natural language queries.
We've grown up with search engines and tend to use them in a very specific way. We quickly got used to boiling our questions down to one, two or three keywords and entering these into search engines in artificial ways until it produced the results we were after. This method of searching is completely different to how we would ask questions in real life.
Over time, how we search online has got more complicated, and now includes things like voice search on mobile and smart devices that more accurately reflect the intricacies of human speech. Search engines have needed to keep pace with this and return relevant results. Google completely overhauled its processing engine, Hummingbird, and has been progressively testing and including machine learning elements to help it process these queries at scale.
BERT is a new development in machine learning, intended to help Google understand the correct context of complicated, natural language queries and return more relevant results to users.
How does it work?
Machine learning programmes have to 'train' themselves using time and data. Typically, initial results are a bit sketchy, and then improve significantly with more data and the longer the program runs.
For example, here's . At first, it's a bit rubbish, but after four hours it figures out a tactic to get the best score.
What can happen, however, is that limitations appear when the program deals badly with certain situations. This becomes apparent when trying to get machines to understand natural language. Human speech and text are riddled with ambiguities and complexities that we generally have no problems in understanding but present real difficulties for machines.
There are various methods used by machine learning programmes to understand language, but they all have their drawbacks. Some use unidirectional (left to right) contextual analysis, for example. The problem with this is that the meaning of a sentence can change dramatically with the final word, so any kind of predictive software will have no idea what that sentence is about until it's completed.
For example:
I went to the bank for a [job]
I went to the bank for a [withdrawal]
I went to the bank for a [robbery]
These are all quite different contexts. Unidirectional models would only make sense of the context of 'bank' once they had seen the whole phrase. BERT is Bidirectional, so can track words in front of and after the keyword being tracked, so can gain valuable clues about the context and meaning of how a word is being used ('bank' as employment, service or criminal endeavour, in this case).
Next up is handling ambiguity and reference. Words in English can sound the same or be spelled the same, but have different meanings depending on context, such as:
Lead – a dense metal element with the atomic number 82
Lead – a rein or leash on which an animal can be tethered or led
Lead – to take the initiative in a situation
Lead – a cable carrying electricity or an electrical signal
Lead – the principal person in a production
Lead – the introductory paragraph of a news story
Then there's the issue of pronouns, and which entity they reference. Here's an example:
He comes downstairs. Morgan says cheerily, "You're looking well, considering."
The truth is about Morgan Williams—and he doesn't like him any the less for it—the truth is, this idea he has that one day he'll beat up his father-in-law, it's solely in his mind. In fact, he's frightened of Walter, like a good many people in Putney—and, for that matter, Mortlake and Wimbledon.
'He' in the first two instances refers to the character of Tom, who has just been beaten by his father, and the remaining instances are for Morgan, Tom's brother-in-law.
Keeping track of which entity is being referred to as pronouns change place, even when they're not in clumsy prose, is the sort of thing machines struggle with and frequently get wrong.
To help them, probability models are used. Systems like WordSim353 dataset show training models where human graders have assigned a similarity score between different words. However, even this won't cover every possibility, and like any other supervised system of machine learning it is dependent on humans going through and tagging the data. This wouldn't be possible at the vast scale Google requires, which is one of the limitations Google Pygmalion, the team of manual linguists working on Google Assistant queries, has run into.
What BERT does is identify ambiguous words and the correct meaning of the sentence based on the other words that are in it. So, for example, if I talk about a 'bank job' requiring a ski-mask, gloves and a shotgun, BERT will probably understand I'm not referring to a career on the customer service desk at my local branch. It encodes the sentence and gives a weighting to each of the words based on contextual probability.
By changing the focus of the target word, it can identify relationships between entities in the sentence, in case they are used as a subject or referenced with a pronoun. This is encoded and decoded by a mathematical transformation process (the -ERT part of the name), which puts the text into a mathematical vector. This has been a part of machine learning and AI processing for a while, because computers can process vector code calculations much, much faster.
Google states BERT is valuable "particularly for longer, more conversational queries, or searches where prepositions like 'for' and 'to' matter a lot to the meaning." This means BERT will primarily impact long tail keywords, which are searched less frequently but are more specific in nature, and conversational queries.
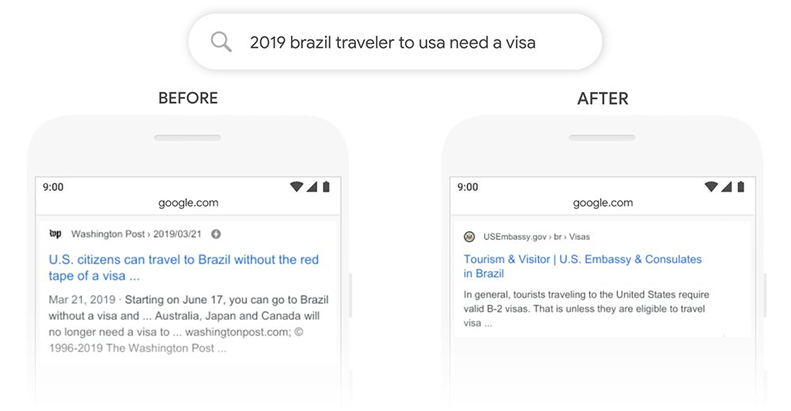
Very small changes in the language of a sentence can be picked up. The example Google gives in its blog post about BERT is the word 'to' in the phrase '2019 brazil traveller to usa need a visa' picking out a specific result for USA tourism visas at the Brazilian Embassy.
BERT has other advantages, too. It uses random masking to prevent target terms passing through the transformation process during training. This would end up skewing the weighting score by creating a sort of loop.
Randomly changing the word it masks during the training period helps identify 'edge' cases: words that might be ambiguous or refer to different subjects in a sentence. This results in a high accuracy of prediction for the 'masked' term so BERT can do a good job of predicting the term, simply based on other words used in the sentence.
It's also the first machine learning tool to be used without supervision on pure plain text (Wikipedia, in this case) as opposed to a limited text collection that had been carefully pre-tagged by linguists.
And lastly, of course, it learns by fine-tuning on all those wonderful eccentricities and idioms of language that crop up as exceptions.
Is there anything BERT can't do?
The reason why it's being incorporated into Google's query processing is that it does what a whole bunch of other natural language processing tools did, only much better.
When comparing BERT against other natural language processing systems, it scored an impressive 93.2%, compared to a human performance of 91.2%. However, it's still not entirely reliable compared to human reader.
Research by Allyson Ettinger showed that BERT can struggle with negations, although one of tests mentioned in the NEG-88 test is ambiguous: 'tree' is used as a mismatch for the term 'robin'. But if you're a keen gardener, you'll be aware there is a garden shrub tree called that.
In any case, it's worth bearing in mind that the tests are done on the 'vanilla' BERT that's been pre-trained on Wikipedia. Google will be using a version that is much more advanced. It would be interesting to re-test the BERT model once it had trained on some horticultural data to see if the negation error was as prevalent.
Is this new?
Not really. BERT was released as Open Source by Google on Github in October 2018, so people could implement it on their own neural network systems. Google itself acknowledges that the system of randomly masking words to check readability goes back further too – it's known as the Cloze procedure and was proposed as a model in 1953 by Wilson Taylor.
The use of bidirectional context is nothing new in practical education. About 25 years ago, I was introduced to the COBUILD dictionary; a project between The University of Birmingham and Collins to produce a dictionary for those learning English as a second language. Research found that providing a definition of a word in language context was the best method, with the optimal length being 15 words each side of the defined term.
One step further, this type of contextual analysis was run on the works of Shakespeare to test the notion if multiple authors were responsible. Spoiler #1: it's mostly written by a single author, but did highlight areas suspected to be 'patched' by other writers where the original text wasn't available in compiling the First Folio. Subsequent tests have been done to compare similarities with other Elizabethan and Jacobean playwrights. Spoiler #2: results are wildly inconclusive.
Various models of natural language understanding have been created and tested for some time. BERT has created a stir in this field as results have shown dramatic improvements on other processing models.
The Open Source BERT, which has been pre-trained on Wikipedia, is just a starter. The idea is that users can take the model and apply it to their own data sets, allowing it to learn and specialise. There is a version on Google Scholar, Facebook and Microsoft have used BERT applications on their own model, and Google's new search processing filter will also have its tweaks and modifications that won't be part of the basic code.
What are the SEO implications?
Predictably, as with any confirmed Google announcement, there has been a flurry of speculation about what BERT means for search. Contrary to industry misconceptions, BERT is not tasked with assessing or scoring websites. This means it is not a direct part of the ranking algorithm and it cannot be 'optimised for' in the traditional SEO sense, like removing bad links or thin pages in a content quality update for example.
BERT is a method of processing queries so that Google will be better able to understand what results to serve for ambiguous or specific searches. As a result, an estimated 10% of search results will be affected and, as with any change, there will be winners and losers.
Search Engine Land features an excellent article by Dawn Anderson which will run through all you ever wanted to know about BERT and NLP models generally.
One clear implication is that if you are not already writing content aimed at your human customers, then BERT's introduction won't help. To be honest, there have been enough developments in search that existing content which rams a target keyword into boilerplated, unhelpful text should have been on the slide for quite some time.
Most sites should and have been writing content to answer needs for customers around their main conversion journeys. If so, then this may get rewarded by connecting a few more of these detailed pages with a relevant search query. Given that Google sees 15% of new searches every day, and BERT allows further scrutiny into the intent of those searches, it would not likely be a huge volume of traffic.
One major potential change is in rich snippet display. By understanding more detail around a query, Google may surface different results in snippets, or choose to display rich snippets for more, or less search queries. How this impacts on sites will vary.
Some may find a clickthrough boost or better brand search traffic if they are featured, others may find that the rich snippet is Google 'stealing a click' and that clickthrough goes down – which can happen, especially with FAQ-style content. You will need to monitor results, check the SERP presentation and evaluate if rich snippet visibility is helping or hurting, although choosing to surrender a rich snippet to another site may not help your cause either.
Which results Google picks for snippets may also change too. Rich snippets usually feature results from pages with high organic visibility, but will this change and show deeper pages? Possibly. Google has stated that it has been using BERT in featured snippets across two dozen countries already, using the additional data from English to train versions in other languages where there is less content, so it's also possible that like RankBrain, changes have already happened and no one really noticed.
The only way to 'optimise' for BERT is to ensure that content is well written and reads naturally to a human reader. If your traffic drops as a result, determine where the losses have occurred and consider if the lost traffic is relevant. Because BERT is primarily about improving Google's understanding of the keyword, it is possible that lost traffic was already low value and your conversion goals are not similarly impacted.
If concerns remain, objectively assess the pages that have lost traffic and consider how they can be improved from a user's perspective. Ask yourself the following questions:
Does the content provide clear and unambiguous information, or is it difficult to read and confusing?
Are there gaps in the information or further questions that warrant answers?
Is it easy for the reader to find out where to go next and how to find more information if they need it?
Understanding user intent
All searches have an underlying need that caused the user to turn to a search engine. This is known as the 'intent' – identifying this helps determine how content can be optimised to meet the need.
User's needs generally fall into one of four broad categories that can be used as a starting point:
Informational ('I want to know') - seeking advice, answers to questions or how to understand something
Transactional ('I want to buy') - a clear desire to purchase a product or service
Navigational ('I want to go') - a search for places or other info that indicates a desire to visit
Instructional ('I want to do') - a need to complete a task, which may include search for relevant tools
To create content that delivers against search intent, think about user needs and the best ways to satisfy them through content and functionality. Ensure that content is written with users in mind – reduce your focus on including keywords for SEO. Consider what your users will need next, and facilitate those journeys.
What has Google been saying?
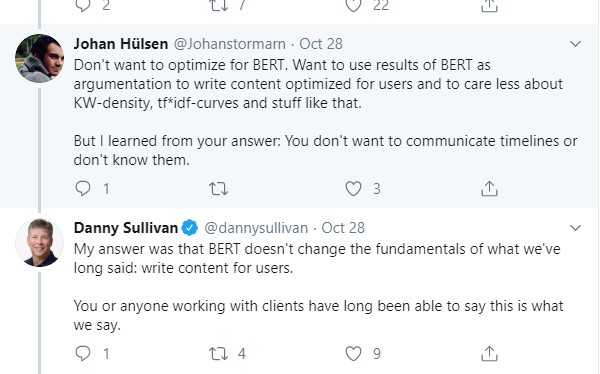
Unsurprisingly, Google has simply been re-iterating its previous advice about writing content for people, and not trying to optimise or exploit anything from an algorithmic perspective. Google's public liaison of search Danny Sullivan has stated this repeatedly.
As BERT is designed to understand the context of natural language searches, it makes sense that you need to first – understand what those searches might be from your audience, and second – create content that answers those searches. If you want to learn more about this concept, here's a refresher article on search moments, or failing that, ask some customers, or people who deal with your customers, what their common questions and issues are.
In the meantime – watch this space. Google is using more machine-learning processes in search results and as these learn and develop, we're sure to see new developments and experiments being integrated into search processing.
Keep learning with Fresh Egg
Join our email list like thousands of other marketing professionals to get updates on key industry changes, early access to free resources and exclusive invitations to Fresh Egg events in your inbox.


