
Five ways to supercharge your insurance A/B testing program

By Stephen Courtney|9 Jun 2021
This blog is written specifically for anyone working in the insurance sector looking to supercharge and positively impact A/B testing programs.
When I first joined the insurance sector, it was a baptism of fire. All of the acronyms the technical obstacles; it took me a while to optimise even my own team's processes.
The following tips aren't specific test ideas or design concepts. They are specific suggestions that helped me increase the win rate, broaden my team's capability and mitigate some of the many complications of testing in the insurance sector.
Please read on and discover my top five ways to supercharge your insurance A/B testing program.
"If you can implement just one of these five suggestions, you'll be well on your way to supercharging your insurance A/B testing program!"

Associate Director of CRO
1. Enable innovation through a data layer
Insurers are sitting on an untapped data goldmine. To get a quote, customers must disclose how many kids they have, how many cars they own, their job title, marital status, postcode, age - the list goes on.
Frustratingly, this kind of data is usually tucked away in a database, inaccessible via a 3rd party testing tool. The reason that's so frustrating is that most A/B testing tools allow you to trigger tests using custom JavaScript conditions. That means, if your testing tool could only read that data, you could use it to trigger all kinds of personalisation campaigns. That's why a client-side data layer should be on top of your IT/dev team wish list.
A data layer is just a posh name for any end-point or object that exists solely to surface data variables in a web application. One such example could be a simple JavaScript object containing an array of insurance quote variables. Queried from your browser's developer console, you can use this kind of object to trigger experiences from within your client-side test code.
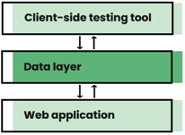
You'll need the devs to build it but, once in place, all kinds of innovations are possible without having to bother them further. Let's say you offer a 10% discount when customers insure their second car with you. Wouldn't it be nice to shout about that? Sure, you could show a promotional banner to everyone, but maybe most of your users only have access to one car. A better approach would be to suppress this banner for them or show them a different message entirely. With a data layer like I've described, this becomes easy and has no additional development requirements - a win moving forwards!
A few suggestions before you brief in work:
- Map out as many potential use cases up-front to save you regularly asking IT to add new variables
- Keep the structure flat, i.e. one long list of variables as opposed to nested groups of variables - this makes it much easier for developers to navigate
- If you're working on a single page app, you might want to get IT to dynamically populate a "page" variable from the app's current state. That could save countless page/URL tracking headaches down the line
- Add responses from third party services.
- If a DVLA lookup fails or the customer's card is declined, your A/B test data could be artificially deflated.
- Adding 3rd party response identifiers into your data layer can help you remove this noise from your results.
- Think about other potential sources of noise in your A/B test data. Is pricing activity impacting your test results? (see next section)
2. Track your pricing algorithms
Price optimisation is a big thing in the UK insurance industry. Pricing teams make countless tweaks to their algorithms. At any one time, they may have 4 or 5 major algorithms running simultaneously, each undergoing regular tweaks (see examples below). The frequency of change makes it impossible to avoid cross-over with CRO tests, all of which can play havoc with your results.
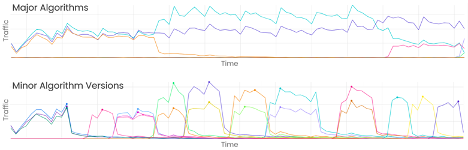
Let's imagine you're running an A/B test to increase add-on sales while your pricing team are trialling an algorithm that happens to have an incredibly high add-on purchase rate. If, by random chance, your variation receives a higher proportion of its traffic from this algorithm than control, it will skew the data.
The ideal solution is to control traffic allocations at an algorithm level, but this usually isn't possible for technical reasons. A perfectly workable solution is to track these algorithms, build segments from them and conduct post-test analysis on these segments to identify any potential bias. Most of the time, you'll find there isn't an issue. With big enough sample sizes, traffic distributions across algorithms tend to even out. However, if you don't check for bias, you could end up making all kinds of bad decisions.
We help businesses develop in-house A/B testing excellence.
3. Release IT changes one aggregator at a time
When Netflix and other testing champions can't use a randomised control test, they turn to something called 'Quasi-Experimentation'. In Netflix's case, this involves using geo-location as a dimension to allocate users into rough test and control groups, i.e. users in London will see the test; however, users in Paris will see the control. Measuring impact requires a form of before / after analysis called Difference in Differences (aka diff-in-diff). Simplistically, if users in London suddenly increase their watching time by 5% while those in Paris only increase by 1% over the same timeframe, the difference (in the differences) is +4%pts. You assume London's trend would have run parallel to Paris' without the test.
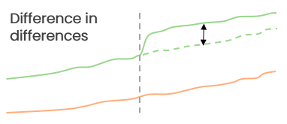
If you are using an A/B testing tool, you might be thinking, "why would I need this?" Well, what happens when IT implements your winning tests?
Are they using server-side testing to A/B test their releases? If not, how can you accurately measure the true impact of your changes in an environment where your pricing team is constantly tweaking prices (see the previous section)? If IT puts your changes live the same day as a significant price cut, how will you un-pick the impact of your changes vs the effect of the price cut? I guarantee the pricing team will snaffle up that benefit quicker than you can say, "but we ran an A/B test".
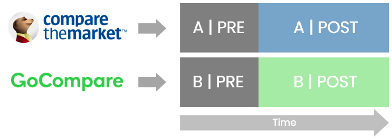
What you need is some approximation of Netflix's location-based test/control cells. Thankfully, the insurance industry has price comparison websites (a.k.a. "aggregators"). When releasing a new feature, instead of launching straight to 100% of traffic, make sure IT build in a 'switch' so that you can toggle that new feature on or off based on traffic source, e.g. if a user comes from Compare The Market, serve the new feature to them. If they come from Go Compare, do not serve the new feature.
4. Give Bayes a chance: manage risk better
Business leaders love the phrase "marginal gains". It was made famous by Dave Brailsford during his time as General Manager of Team Sky. In a nutshell, the marginal gains philosophy stated that if you found 1% improvements across all aspects of cycling, they'd have an impact greater than the sum of their parts.
The problem for most CRO teams is they often don't have enough traffic to achieve statistical significance on improvements as small as +1%. There are a few advanced ways to increase a test's sensitivity (bootstrapping, CUPED), but these usually require data science resources. To make matters worse, in the insurance sector, every test requires many sign-offs and a large amount of QA. By the time you're looking at test results, the total sunk costs for a test can reach hundreds of hours across the team. Given the investment, is there a way to implement more of those inconclusive +1% tests and calculate the risks involved? Well, with Bayesian statistics, the answer is yes!
If you're reading this, I'm assuming you know about 'statistical significance' and 'the null hypothesis'. These phrases come from the Frequentist branch of statistics, which was originally developed to support formal research fields like medicine. As such, it's inherently strict. If you're doing it right, you're calculating the required sample size beforehand, you're picking a fixed stopping point, and you're not peeking at any results until then. If you haven't achieved significance by then, you either tweak something, re-test or move on. If you want marginal gains, though, this approach can lead to many 'type 2' errors.

The Bayesian approach, while no less rigorous, is arguably more flexible. For example, let's say you ran an A/B test where each variation received 10,000 visitors. Version A got 5,000 conversions, and version B got 5,100.
Using a Frequentist calculator (specifically a two-tailed z-test), these numbers give you a 2% uplift but are inconclusive. Whereas a Bayesian calculator will tell you "there's a 92% chance your test will beat the control, but there's also an 8% chance control will beat your test". I think most stakeholders would take those odds.
So, if you haven't quite hit significance, stick the results through a Bayesian calculator and put the decision in the hands of your stakeholders. You'll be pleasantly surprised how often they're willing to take the risk.
5. Raise your profile: embrace being useful
A recent Delloite study stated that "by 2024, 33% of premium volume will come from brand new propositions." With Lemonade in the US and By Miles in the UK, innovative propositions are already starting to disrupt the market.

However, change takes a long time at an established insurer. Legacy technology, overstretched IT teams, and heavy regulation put CRO teams in a unique position of being able to affect change relatively quickly.
Every CRO manager wants the wider business to know and appreciate their team's work. What better way to do that than by being useful to as many departments as possible? For example:
- Help your underwriters make content changes IT can't prioritise
- Run "painted door" tests for product development teams
- Help the marketing department launch banners
- Be problem solvers
I hate to say it but, if that means running a few tests at 100%, so be it. The benefits to your team's reputation and the business will outweigh the risks - up to a point. It seems an obvious point, do make sure you get senior stakeholders to formally accept the risks. It's also worth working out a process with IT, so future releases don't cause headaches. Most importantly, though, don't lose sight of your objectives.
Incorporate this work in a controlled way. For example, you might want to collate a separate prioritisation matrix for "strategic tests" and incorporate one of these into your program per month. Here are some things you could ask yourself when deciding if a test is "strategic":
- Will this work help a department we haven't worked with before
- Does this work already have the attention of senior leaders?
- Are there benefits already assigned to the work?
If you're worried about burning through your budget, the following response is helpful: "Yes, we'd love to help, but you're gonna have to pay for it!"
Conclusion
Having learned many of these tips the hard way, I hope they help you avoid some of the same mistakes. In summary:
- Maximise the data goldmine you're sitting on
- Speed up innovation by making that data more easily accessible
- Track your pricing algorithms and use them in post-test analysis to identify biases
- Use Bayesian stats to communicate the risks of implementing marginally positive yet inconclusive tests
- Embrace being useful to grow your team's influence in your business
If you can implement just one of these suggestions, you'll be well on your way to supercharging your insurance A/B testing program!


A/B test program implementation support and advice
We help businesses integrate and develop A/B testing excellence in-house. Our A/B successful test philosophy is simple, we keep the winning solutions and learn from the tests that don't make the grade - we help you do the same.
Get Fresh Thinking and Stay Ahead of Digital Marketing Trends
Subscribe to our Fresh Thinking Newsletter and get...
✅ Exclusive invites to our helpful knowledge-share events✅ Curated news roundup of pertinent and topical industry news
✅ Early access to our industry resources and insights.
Register for Fresh Thinking and keep up to date with our helpful digital marketing news insights.