
The Top 20 Milestones in Google’s 20 Year History

By Stephen Jones|6 Dec 2018
It’s 1998! A Titanic year in film with James Cameron’s ship-versus-iceberg blockbuster gathering 11 Oscars and being the first film to gross over a billion dollars; the first two modules of the International Space Station blasting into orbit; and UK consumers wondering if they have to replace their VHS tapes and Laserdiscs with this new thing called a DVD.
Meanwhile, on September 4th, Larry Page and Sergey Brin founded Google Inc. which will gradually overhaul the likes of AltaVista, Ask Jeeves, Lycos and Yahoo! to become the way that 92% of the world searches the internet, and also a company that employs nearly 90,000 people and has a yearly income of over $110 billion. Not bad for a business that started from a garage in Silicon Valley.
So, what have been the top 20 highlights from this period that have radically shifted the nature of search? Let’s take a quick look.
1. Florida Update (2003)
Possibly one of the biggest algorithm updates, Florida shook the retail and SEO industry with a massive revision of search results. Having switched from the “Google Dance” to more regular updates and real-time changes in search results, Florida rolled out changes targeting spam tactics to manipulate search rankings for lucrative keywords. On-page methods that had influenced ranking such as keyword stuffing, invisible text and domain crowding were hit hard, with many brands that had relied on affiliates seeing their visibility wiped out.
Some estimates on ranking changes put the variation in featured sites as high as 98% for some searches, with an average of around 72% for high traffic, commercial queries.
This was a clear shot across the bows for tactics designed to exploit the search algorithm, and was just the beginning of a two-decade process to improve results by eliminating web spam.
2. Brandy Update (2004)
This one sort of sails under the radar a little, but is a nickname for a group of changes that closely reflect the current priorities of Google, and were clearly part of their mission strategy 14 years previously.
- Increase of the index. At that time, there was still a turf war over how much of the web search engines could discover and index (something which Google has comprehensively won). Brandy saw a significant increase in the amount of sites indexed and presented in search results
- Latent semantic indexing. This placed more significance on related synonyms used on a page to determine the topic and purpose of content (further undercutting attempts to “spam” high traffic keywords)
- Link neighbourhoods. Although the PageRank™ algorithm determined value of a page due to backlinks, it started to become more important where these links came from. Links from topically-relevant sites identified in a sector became more valuable
3. Personalised search (2005)
Previously, personalised results relied on logging into a profile which stored settings. With this update, Google started using the user’s search history to customise the results they received. A telling note on the Google Blog announcement said that the “… concept of personalization has been a big part of our lives since some of the team was in grad school in Stanford”, indicating the idea of personalised results being more relevant to users is a core concept being refined to the present day.
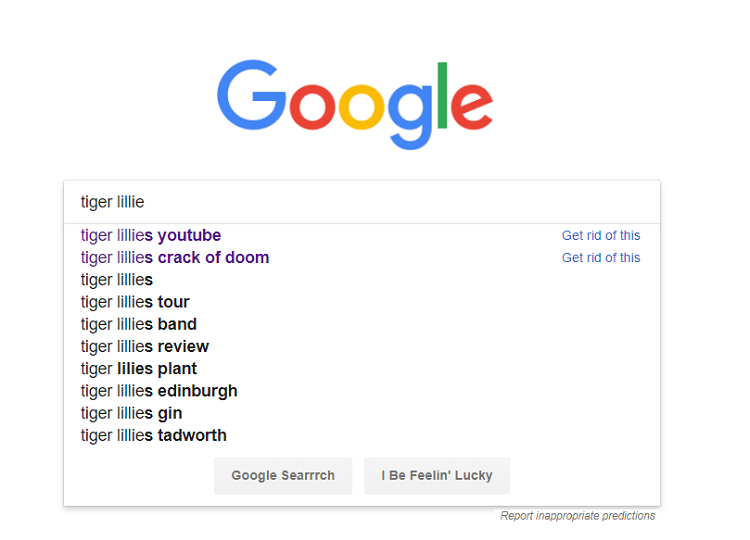
4. Google Local & Maps (2005)
By joining two products together, Google created a strong basis for what it would later identify as “I want to go” micro-moments: enabling users to locate brands and services in local searches, as well as juts places. Was this intentional, or simply a happy co-incidence of two side projects realising there was a potential synergy?
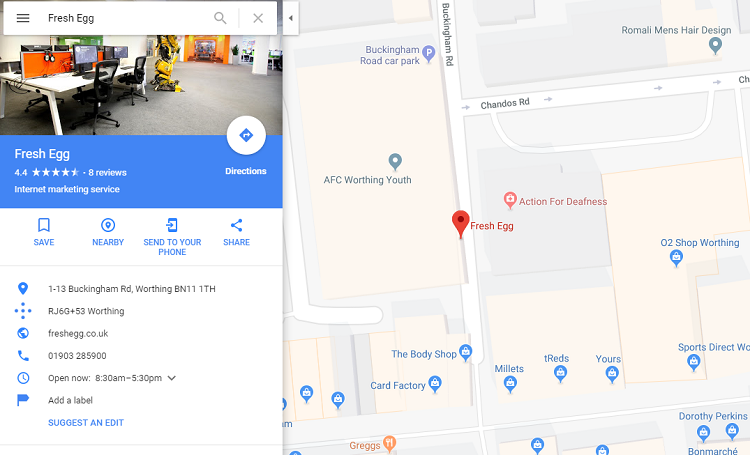
5. Universal Search (2007)
Google then changed the format of search results from the traditional “ten blue links” to an integrated format that blended news results, images, video and local information. This showed a recognition that users did not always want to hunt around on a web page to find the information they needed, but might want to see relevant items highlighted in a variety of formats.
Experimentation and modification of search results formats are still underway, as Google tests which mix of results users find most helpful.
6. Google Suggest (2008)
Another radical change to the original concept of a blank white box in which users would type queries, Google now started suggesting searches related to the key terms in the query box. As well as surfacing popular and frequent search trends, this also provided a sometimes hilarious and often disturbing insight into what lots of other people were searching for.
7. Real Time Search (2009)
Major developments with Google have often focussed around news and the reliance users have for recent and breaking information. Real Time Search integrated a news feed into results for searches deemed topical, featuring latest tweets, posts in Google new, topical blog content and other sources.
Google would later have a falling-out with Twitter, removing the feed content and disarming the “Tweetserping” tactic, but, as Twitter remains the most timely social media platform, they’ve become BFFs once more.
8. Google Places (2010)
For some time, there had been a confusing number of ways to register a brand in local results, and Places was the official migration of what had been the Local Business Center into what was – hopefully – an integrated platform.
Some creations arrive into the world complete and perfect; others are born from pain and destruction. From the convoluted authorisation process, to the duplicated results across merged platforms and the seeming lack of official support, it would be fair to say this fell into the latter category. However, this now forms the backbone of the Google My Business system, from which Google takes authoritative company information for search results.
9. Caffeine (2010)
Not an update, exactly, but an architectural overhaul of Google’s indexing system. With the push to discover, index and rank new information from increasingly diverse sources, the previous system of dealing with all this information wasn’t up to scratch. Google launched an extended period of testing, even showcasing progress to SEOs to reveal how new sources of information could be indexed directly and be available in results without the previous delays caused by their “layering” system.
In addition to being able to handle the surge in information creation on the web, the new architecture could also handle this at speed, retaining one of the features that helped make Google such a popular search engine in the early days of the internet.
Designed as a “future-proofing” development, this would actually be in place for just three years before another major overhaul was required.

10. Google Instant (2010)
Another refinement of predictive search, Instant was developed to suggest a number of suitably white-listed search results as users typed their query. The initial reasoning behind the update was sound: saving users time on searching for results (estimated between 2-5 seconds per search) would likely result in a better experience, with SEOs and clients worrying what would happen if their listings did not immediately appear in the range of suggested options.
This feature didn’t have such as radical impact on the search environment as feared (mainly due to the increasing acceptance that page #2 of Google results wasn’t the best place to be – instant, suggested or otherwise).
It was eventually dropped due to incompatibilities with search behaviour on mobile devices, as Google shifted its priorities to a mobile-first mindset.
11. Panda (2011)
Google had successfully countered many forms of web spam that had effectively ruined the quality of results with other search engines, but was still facing an issue with popular queries infiltrated by low quality websites using tactics to inflate search ranking. Users were starting to struggle to find important information on medical searches, for example, without having to wade through badly-designed sites that were trying to monetise through adverts or affiliates. This potentially threatened their paid advertising: Google’s principal revenue stream.
Step forward the Panda update, named after a lead engineer and one of a series of quality updates that would eventually roll into the core algorithm and run real-time. Each update tweaked the threshold for quality, de-valuing pages that had little content, no authority, or used scraping or auto-generated methods for populating information.
Although cagey about the exact nature of the update and its subsequent iterations, Google did release a set of questions that it encouraged webmasters to ask themselves, and the general assumption was that Panda managed to recognise and assess these factors programmatically on a site.
It’s interesting that most of these initial questions are still included – almost unchanged – in the latest Search Quality Evaluator Guidelines released by Google.
Panda went from a series of staged updates and rollouts to a more integrated approach with the core algorithm. The last “known” update was in 2015, but it’s a good bet this is constantly revised and tested to identify new forms of content spam.
12. Schema.org (2011)
The joint decision by Google, Microsoft and Yahoo! to adopt support for schema is still being felt today as Google introduces new featured snippets for different types of information. Behind the scenes, a standardised approach to recognising the purpose of data (as opposed to simply matching the characters in a text string), allows search engines to create a semantic web, and serve highly relevant results by understanding the intent behind a search. Testing shows Google frequently identifying structured data formats that are not part of its featured snippets portfolio, or have partial markup, so this is likely to be an important factor in how it understands web data and presents it in results.
13. Search Encryption (2011)
In response to what it claimed was a privacy complaint, Google started encrypting large amounts of organic search queries in Google Analytics. Previously, where webmasters would be able see organic queries used to find the page (and alter their content and ad remarketing strategy to suit), they now saw “not provided”.
As the trend of online security progressed and more browsers moved over to encryption as a defaults setting, effectively all the organic search query information on Google Analytics was rendered useless. It was no longer possible to cherry pick key organic queries. Webmasters (and SEOs) had to make do with paid search data, sampled data from Search Console, or doing the hard work and figuring out what their site audiences would be searching for.
14. Venice Update (2012)
Although not given a specific launch date, the Venice project was designed to promote local search results and integrate local signals for queries. With the rationale that users would find results near to then more useful, this was the first of a number of locally-themed updates (such as Pigeon, in 2014) that surfaced information near to the user, or the location they specified in their query.
Localised results are almost second nature to us now, and probably the primary result we expect when using a mobile device to search for a brand or location. At the time, however, a number of online retailers with a national market, but single business address, found their search traffic severely limited by localisation.
15. Penguin
The left-handed dagger to Panda’s rapier, Penguin was another spam-fighting quality update to address the issues of poor quality linking. Although the range of ranking signals in the algorithm was already complicated (and likely getting ever more so with the improvements in search), creating a large number of backlinks was still an effective tactic to artificially boost the visibility of a website.
Penguin effectively obliterated most of the established methods of automatic link creation virtually overnight, and over successive iterations continued to target link-related spam tactics such as over-optimised anchor text, link directories, link networks and forms of paid linking which were against Google’s guidelines. Sites in violation could see traffic drops as links were devalued, or find themselves getting a “nastygram” in Search Console telling them they had been penalised.
Some major brands were caught out by Penguin, and suffered major visibility loss during some key retail phases until they were reinstated. Google even devalued most of the mainstream media websites for selling advertorial links. Other popular tactics such as sponsored blog posts also died out as the links became a toxic liability.
Until Penguin was rolled into the main algorithm in 2016, sites were reliant on updates and refreshes to re-evaluate the website after clean-up activity. As these became infrequent, some sites had to operate for nearly two years under effective traffic penalisation for bad linking behaviour. Some businesses had to start over with new domains, or even shut up shop completely.
Between Panda and Penguin, the initial mission goal to clean up Google SERPs was almost a complete success. Although attempts to subvert loopholes still emerge, it is far less trouble to work within the Google recommendations on linking and content than against them.
16. Knowledge Graph (2012)
Google started introducing a Wolfram-Alpha style information panel into SERPs in response to queries about known things. This was based on an intelligent model that understood the relationship of real-world entities to properties associated with them. In addition to using structured data to understand things, events and people, it delved into other databases such as Wikipedia and Freebase, supplemented with refinements based on search queries.
The Knowledge Graph continues today, showing up in response to an ever-increasing range of queries. As these results are designed to answer a query within search results themselves, critics have noted this keeps users within Google and prevents clickthrough to websites listed in results.
17. Hummingbird (2013)
In the same way the Caffeine update was a re-structure to handle the new volume and complexity of user search, Hummingbird was required to cope with the new demands placed on Google. As well as the accelerating rate of content creation on the web (and the need to sort out the best results for users), there was now the additional complexities of Knowledge Graph, relational properties, search intent and the use of voice search on mobile to look for things.
Google compared Hummingbird to rebuilding an engine rather than simply upgrading it. At the same time, it hired Professor Hinton who had pioneered work on machine learning and patterning results that could be processed quickly by machines. This must have had some bearing on their need to understand and interpret “conversational search” as well as future projects using AI.
18. HTTPS:// (2014)
Google confirmed that it would give preference to sites that were hosted on a full HTTPS:// certificate, and would award a slight rankings boost (although no-one has ever really found what that was, or how much of a benefit it provides).
This was in step with many other web authorities which saw the entire future development of the web being reliant on a secure environment (not just a shopping cart where you can buy things). It also formed another layer of trust with websites, as many low value networks would not necessarily go to the time and expense of purchasing a security certificate.
User awareness is slowly improving about online security and the risk of losing data via non-secure connections. Browsers too are taking more steps to highlight trusted connections. The new version of Chrome now treats HTTPS: as default and will notify users when a connection is not secure. Mozilla has stated its intention to revoke trust of security certificates issued by Symantec (the large Cybersecurity software provider) due to lack of quality control and validation procedures issuing SSL certificates to websites; Google may do likewise.
Web security measures, especially in light of the global environment, will only become more stringent as time progresses
19. Mobile Update (2015)
AKA “Mobilegeddon”, many digital marketers had been hearing the phrase “this is the year of mobile” for the past decade or so. Google had been keeping a close eye on internet usage habits, and had seen mobile searches exceed desktop for the first time that year. Now, the year of mobile had really happened.
Warning people in advanced of the update, Google announced it would rank mobile-friendly sites differently from April 21, and mobile unfriendly sites would be “ranked accordingly” (ouch!).
The actual impact wasn’t immense, but did indicate the clear path Google was taking with mobile (if the reorganisation of business units under the mobile division wasn’t a big enough clue). This paved the way for a mobile-first development ideology, mobile-first ranking, and a suite of tools to assess the performance of sites on mobile devices for webmasters.
The mobile switch is likely to be the first steps in a series of best practice guidelines that are device-agnostic, allowing for the use of new technology and devices that are integrated with the web.
20. RankBrain (2015)
As we get closer to the future, it’s perhaps fitting that this is the last milestone in Google’s history (so far) – the use of machine learning in the ranking algorithm.
The initial horror from SEOs that machines were now taking over SEO was mitigated to a point when it was revealed that RankBrain had been working for months already, and not only had humanity not been enslaved to the Machine Overlords, but no-one had really noticed much difference. Google had also reported much greater accuracy of RankBrain in quality assessment than its human evaluators.
The fact is, that unless you have a particularly rare talent, processing large, complicated and messy groups of data is insanely difficult for humans, but the type of task at which machines excel (if they are given the right instructions). With the ability to learn as they progress, this makes neural networks the perfect solution for doing the “heavy lifting” and allowing human insight into the product and future direction.
The emergence of neural network and machine learning systems for marketing has already started, with solutions appearing to help break down and analyse web traffic, social media, understand images and provide insight that it would take humans hours – or days – to sift through.
That’s all in the last 20 years. I’m curious what the next two decades will bring (and what format I’ll have to re-buy Titanic on).